

文|万湑龙
3月17日,在被AI圈万众瞩目的英伟达 GTC 大会上,理想汽车基座模型负责人詹锟正式发布了下一代自动驾驶基础模型MindVLA-o1。次日,理想汽车CEO李想便在B站发布了与詹锟的对谈,用极为通俗的语言对这项硬核技术进行了深度解码。
这段11分钟的视频里第一个章节名非常有意思——物理AI卡在哪了?

我相信李想提出的第一个问题也是很多人感兴趣的。那就是开车这件事对于我们普通人来说并不难,但是现在全世界最聪明的人、最顶尖的硬件和最庞大的算力,似乎都投入到了自动驾驶上,技术发展的进度却鲜有实质性的突破。这种投入产出比很难让人理解。
而其中的卡点,就是缺乏对真实3D世界的理解能力。
过去的模块化方案(感知、规划、控制层层剥离)就像是僵化的击鼓传花,只要遇到没写进代码里的长尾路况就会彻底罢工,而当下被全行业奉为圭臬的纯端到端模型,虽然反应速度变快了,却沦为了一个知其然而不知其所以然的黑盒。
因为这里藏着两个致命的软肋:第一,它在看2D视频做题。就例如BEV,就很容易丢失高度信息,在这个基础上做AI训练,本质上就像坐在电脑屏幕前,通过死记硬背海量的2D视频来形成肌肉记忆。还有容易丧失语义的OCC,这些尝试都是试图去理解真实的3D物理空间,但无论是立体纵深、还是物体属性,都会对它们造成困扰。
第二,它只有直觉没有逻辑。它只依靠概率学进行条件反射,完全缺乏逻辑推演能力。它无法解释自己为什么突然变道,更不会在危险发生前进行“思考”。一个没有真实三维空间概念、只会凭直觉盲猜的黑盒系统,注定无法在瞬息万变的物理世界里,为我们的生命安全提供绝对的兜底。
所以,理想MindVLA-o1的颠覆性在于,它真正将三维环境理解、逻辑推理与动作生成在底层实现了完美统一。它或许已经揭示了下一阶段自动驾驶模型竞争的逻辑变化——不再是单纯地“让车开得更好”,而是谁能率先造出一个具备感知、思考和行动能力的“物理世界通用人工智能”。
演进的宿命:为什么
物理世界的AI必须重走“人类进化之路”?
理想的技术路线为何在此时发生坚决的转向?
李想举了一个通俗的例子:人类之所以能够游刃有余地处理复杂驾驶场景,是因为我们在 0-6 岁的孩童时期,就已经通过无数次的扔球、奔跑、摔跤,在基因和大脑深处完成了对3D空间的预训练。而开车,只是在基于我们对于真实的3D空间有了深度理解之后,“无他,唯手熟尔”的常规演进。
詹锟在解读技术时也印证了这一点。为了补齐 AI 所缺失的这段“童年空间训练”,理想彻底抛弃了二维降维方案,通过原生3D ViT结合激光雷达点云,直接在底层还原了 3D 空间的真实语义和几何结构。

在训练过程中,理想汽车采用以视觉为核心的3D ViT Encoder(3D视觉模型编码器),并利用激光雷达点云作为三维几何提示,引导模型理解真实空间结构,使其在单一表示中同时具备语义理解与三维感知能力。
而为了进一步提升环境理解能力,理想汽车在训练中引入了前馈式3DGS表示(Feedforward 3D Representation),将场景分解为静态环境与动态物体分别建模。模型不仅能理解当前场景,还可以预测未来的状态变化。训练中使用下一帧预测作为自监督信号,同时学习深度信息、语义结构和物体运动。最终得到的3D ViT表示融合了空间结构与时间上下文信息,为后续决策模型提供高质量的3D世界表示。
有一个不容忽视的产业定律是:没有对3D物理世界的原生理解,就不可能诞生真正的自动驾驶 。纯靠二维视频“死记硬背”海量题库的AI,充其量只是一个拥有极快条件反射的机器。只有真正掌握了三维空间认知,AI才算拥有了在物理世界生存的坚实底座。
在这样的行业背景下,理想 MindVLA-o1 展现出了降维打击般的优势。
一方面,它实现了从盲盒直觉到透明逻辑的升维。MindVLA-o1 并不排斥端到端的快反应,但坚决拒绝“纯直觉”。它在极速的神经反射之上,叠加了一层类似人类前额叶的“慢思考(System-2)”机制。结合多模态语言能力,它让智驾黑盒变得透明、可解释。另一方面,它实现了从“2D模仿者”到“3D世界理解者”的跨越。通过原生的3D世界观,它不再只是识别二维像素,而是真正理解了空间的立体纵深与物体的物理属性。
核心杀手锏:
“多模态慢思考”与打破数据死结的指数级进化
那么,MindVLA-o1 在实际运行中到底强在哪里 ?
首先,它彻底打破了纯端到端“直觉驾驶(System-1)”的盲区,深度引入并重构了“慢思考(System-2)”。但我们深入了解后发现,这种“多模态思考”绝不仅仅是常规的逻辑推导,它最核心的杀手锏在于赋予了机器对未来场景的强大想象力。
譬如说詹锟特别强调的“预测式隐世界模型(Predictive Latent World Model)”的作用。当车辆遇到错综复杂的无灯路口时,它不会盲目地根据历史概率做选择。相反,它会在极低算力消耗的“隐空间”里,在零点几秒内预演并推演出未来几秒钟各种可能的动态走向。在完成了这种对未来的“脑内彩排”后,再由动作专家(MoE)模块输出最安全、平顺的轨迹。
其次,这项技术打破了自动驾驶面临的终极数据死结。现实物理世界中,极端的事故数据是极其稀缺的。为了跨越这道鸿沟,理想依托自研马赫100芯片的强大算力,构建了一个高度可控的世界模型(MindSim)。这使得 AI 能够在一个无限逼真、且可以随意改变环境变量的虚拟世界里,进行高频的“左右互搏”与闭环强化学习。
而我们稍微把视角抬高一些,以更宏观一些的角度来审视这套系统的时候,就会发现一个很有意思的现象。MindVLA-o1从视觉感知到世界理解和推理、到行动决策、再到强化学习持续优化,以及最终的系统协同。这其实就是生物性大脑在学习中的过程——从信息进入视觉皮层,到前额叶进行推理和规划,最终到运动皮层生成具体动作。这种生物进化所筛选出的最优解,也同样可以为机器构建一个可以在真实世界中运行的“数字大脑”。
也只有这样,才会让MindVLA-o1成功地让机器从“被动地被喂养数据”的束缚中脱身,跨越到了“主动去试错与思考”的更高维生命形态。
通吃物理世界:
从自动驾驶到具身智能的“降维打击”
在GTC大会的演示中,令人震撼的不仅仅是复杂的路况博弈,还有一个由MindVLA-o1驱动的机械臂精准地倒了一杯养乐多。

为什么 MindVLA-o1 既能开车,也能控制机器人?
首先在于其底层逻辑的绝对统一。通过解析理想构筑的四大核心架构(MindData、MindVLA-o1、MindSim、RL Infra),我们可以得出一个清晰的结论:这套原生多模态 VLA 架构根本不关心它的神经末梢连接的是方向盘还是机械臂。只要输入视觉和语言信息,它就能输出符合物理学定律的动作。GTC 上机械臂倒养乐多的演示,就是对这一技术普适性的最好证明。
其次,这对于推动整个具身智能产业的发展具有不可估量的战略意义。在所有消费级工业品中,汽车拥有最充沛的电力储备、最强悍的移动算力和最丰富的传感器集群,它是验证具身智能最佳的桥头堡。理想通过造车,率先跑通了这套闭环的 AI 框架,这为未来将技术无缝迁移到任何形态的机器人身上铺平了道路。
在理想汽车所描绘的蓝图中,自动驾驶从来都不是终点,它只是具身智能在商业化落地上最大的一块“试验田”。汽车,本质上就是一台长着四个轮子的超级机器人。而统一的 VLA 模型,正是打通所有物理世界智能体的“巴别塔”。
普通人眼里的MindVLA-o1到底是什么?
剥开这些艰深晦涩的技术外衣,我们普通大众应该如何理解理想的这套硬核技术?
通俗一些来说,它就如同一个“长出前额叶的老司机”。在GTC 2026上的 MindVLA-o1发布会中,詹锟举了这样一个例子——
当我们看到右侧有一辆车准备并线时,系统需要推理这辆车是否会切入当前车道,如果它真的并线,我们应该如何避让,是减速、刹车,还是向左变道?而为了做出更好的决策,系统必须拥有预测未来几秒钟场景变化的能力。
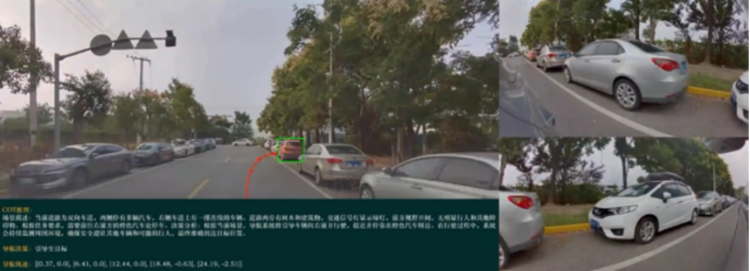
在此刻,大量的预训练就发挥了作用。在做驾驶决策时,模型不仅能够理解当前场景,做出逻辑判断,还可以在隐空间中提前“想象”未来的画面,具象化驾驶决策。
再简单一些说,自动驾驶不仅需要看见世界,还需要预测世界。
任何技术的最高境界,都不在于冷冰冰的算力狂飙,而在于让机器拥有和人类颗粒度一致的逻辑能力和动作习惯。MindVLA-o1给普通人出行带来的最大改变,是让汽车彻底摆脱了一个冰冷“代步工具”的宿命,蜕变成了一个可以让我们充分理解和信任的“数字伴侣”。
如果我们将视线拉得更高,去回顾李想近期透露的理想汽车内部组织架构的大重组,你会发现这家公司的雄心。底层的芯片与 OS 被定义为“脏器系统”,大语言与视觉基座模型是“脑系统”,而线控底盘和能源供给则是“硬件本体”。这种以生物学视角的架构重整,已经完全脱离了传统车企的狭隘定义。
当一家车企开始按照“人体结构”来重构自己的核心研发体系时,它的终极目标就已经不再是每年能卖出多少辆车,而是试图构建一个完整制造“硅基家人”的能力体系。而 MindVLA-o1,便是发动这套庞大体系的第一缕星火。
它不仅跨越了参数内卷的生死线,更是彻底改变了汽车产业赖以生存的竞争维度。它硬生生地将战场从单纯交通工具的智能化,拉升到了物理世界AI基础设施的军备竞赛层面。在下一个时代,掌握了这套VLA原生多模态能力的玩家,拿到的将不再是下一代汽车市场的入场券,而是主导整个具身智能时代的战略底牌。

京ICP备09113703号-1
信息网络传播视听节目许可证: 0110553
广播电视节目制作经营许可证
公司名称:北京车之家信息技术有限公司
中央网信办违法和不良信息举报中心
违法和不良信息举报电话:400-868-5856
举报邮箱:jubao@autohome.com.cn