

大家好,我是肖老师~
前两天,受邀参加了小鹏第二代VLA发布会,给大家分享分享这次发布会的重点,以及我自己的一些看法和思考。
关于第二代VLA,小鹏汽车董事长兼CEO何小鹏自己的评价非常高,认为这是从L2到L4的拐点,是真正通向L4自动驾驶的开端。
他认为,端到端模型已经触及能力天花板,智驾研发来到了分水岭时刻。
过去的2025年,小鹏车卖的不错,但辅助驾驶的进展似乎不如人意,从最初可与特斯拉、华为争锋的状态,进入到跟随甚至有些掉队的水平。
这种感觉不是用户主观感受,小鹏自己也坦然承认,因为这是小鹏的主动选择。过去一年,小鹏的辅助驾驶正在经历一次架构重塑,从第一代VLA到第二代VLA,不是原有架构优化,而是整个推倒重来。
何小鹏认为,原有的架构能够通过不断打磨下限场景,带来能力优化,给用户带来能力提升的直观感受,这也是多数友商在做的事,但无法实现真正从L2到L4的突破。
构建第二代VLA,小鹏从最底层重新思考如何解决自动驾驶问题,即把自动驾驶当成一个物理AI的问题,去解决算力、数据和模型之间的平衡。
因此,小鹏第二代VLA不仅是自动驾驶架构,更是小鹏构建的物理AI基座模型。

主导小鹏第二代VLA设计的,是小鹏汽车通用智能中心负责人刘先明。
这一中心是由自动驾驶中心与智能座舱中心合并而成,全面领导小鹏汽车智能驾驶及智能座舱技术的研发与落地,直接向何小鹏汇报。
刘先明曾就职于Meta、Cruise、地平线北美实验室,长期从事机器学习与计算机视觉研究。2024年3月加入小鹏汽车,初期担任AI团队负责人,2025年10月接替李力耘出任自动驾驶中心负责人。

刘先明指出自动驾驶本质是物理AI问题,并提出了这个公式:L4能力 = 模型 × 算力 × 数据 × 本体。
类似的公式我们也曾多次见过,不同的是,刘先明在公式中又引入了一个本体的概念。他解释称,所谓本体,是指整车部分。
增加了这个本体概念,其实是想指出,物理AI与数字AI的不同。

他进一步谈到,物理世界跟数字世界有很大的不同,前者的难度呈指数级在增长,它输入信号是连续的、非结构化、信息量大,而且不像文字一样容易去做分词。
同时,物理世界还存在一定未知性的反馈、交互。
因此,只有能够做好基座模型的公司,才能做好AI,做好自动驾驶。小鹏第二代VLA的初心,就是要打造一个原生多模态的物理世界基模。

拆解具体的问题来看,在模型层面:
1、如何去做处理连续的、多模态的输入信号?小鹏设置了一套原生多模态的tokenizer,让它以更高效、更原始的阶段去处理、融合多模态信号,避免单一模态带来的偏差。
2、如何应对物理世界的复杂性?这需要一套特别高效的视觉思维链,为了能让它跑的具有实时性,小鹏把思维链处理效率提升了32倍。
3、最后在输出层面,它能实现语言、视觉、行为、动作的多模输出。
刘先明指出,它不仅仅是第二代VLA的基座模型,也是仿真、世界模型、强化学习的基础。小鹏希望实现舱驾联动,让车辆像一个有机的智能体,这个基座模型也是后续做舱驾一体延伸的基本。

刘先明带来一个例子,来解释VLA模型是如何做判断的。
图片中显示,智驾车辆在直行道路上跟随大车做慢行,模型会通过思维链,推演多种可行路径,从安全、舒适、效率、合规等维度进行打分、做出判断,找到一个可行的方案,这些都是系统自动生成的,完全没有其他拼接的策略。
通过这样的方式,系统是能够判断出什么样的解决方案是最合理的。而能够处理复杂场景,正是基于强大视觉思维链的分析能力。

在算力层面,毫无疑问,强大的模型需要强大的算力支撑,才能足够实时的进行信息处理。小鹏根据自动驾驶应用场景,自研了图灵芯片,针对性地设计了底层架构,同时在上面打造了一套AI编译器,让AI模型的运行更加丝滑、高效。
刘先明介绍,小鹏也同时根据了芯片和编译器定制了图灵结构模型。正是因为有了全栈式联合研发,这使得第二代VLA模型在车端运行的速度整整提升了12倍。

一款芯片到底跑的快不快,适不适合自动驾驶,取决于芯片运算效率。
刘先明认为,有效算力等于芯片名义算力乘以算力利用率,后者则取决于算法模型与芯片的适配程度,计算密度越高就意味着芯片利用率越高。这个观点地平线也曾经提到过。
通过上图可以看到,通过小鹏自研芯片和模型结构的深度定制,和编译器的联合优化,将计算利用率提升到了82.5%,对比利用开源模型和通用芯片,利用率提升了三倍。

之前小鹏提到过,一颗图灵芯片的名义算力相当于三颗Orin-X,经过全场景设计优化之后,现在一颗图灵芯片的有效算力能到达十颗Orin-X的水平。

训练端算力来看,小鹏在2025年公开的数据是有10 EFLOPS云端算力。刘先明介绍了另一个维度,即云端算力利用的效率。
刘先明介绍,小鹏不停优化整个模型和训练过程中的容错性、 稳定性和训练效率,以及数据读取的有效效率。
他介绍称,从去年11月小鹏科技日到现在,小鹏一共更新了468版模型,平均每天接近4版。一个上十亿参数的大模型,能达到这个效率,足以证明小鹏的AI基础设施非常强大。
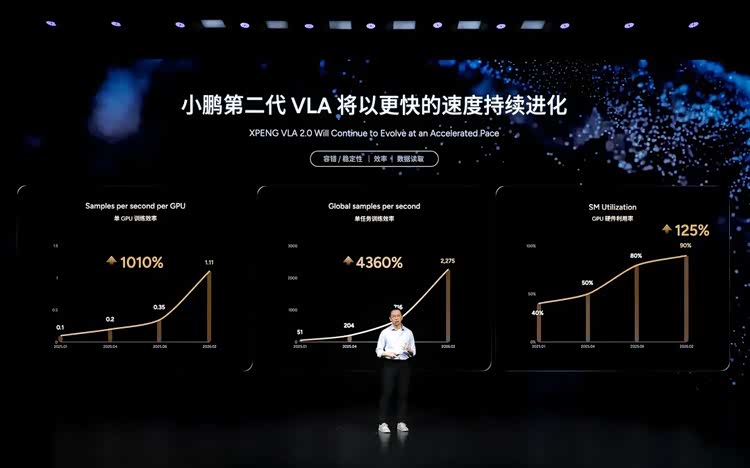
另外几组数据来看,从2025年1月到现在,单颗GPU的运算效率提升近10倍,单任务训练效率提升近43倍,GPU的计算利用率从40%提升到90%。

最后到数据维度,在模型训练中高质量token越多,模型就会越强,泛化能力就会越强。
刘先明介绍,小鹏云端训练高质量数据达到了50PB的规模,这是语言大模型训练20倍左右的数据量。
同时,因为小鹏输入的是高密度的摄像头数据,例如7颗车上摄像头带来的高帧率数据达到每秒53亿个字节。
他表示,这些高密度的输入数据也给小鹏带来更多高质量token,小鹏每版模型训练数据在4万亿Tokens,这是训练一个ChatGPT级别的通用大模型所需数据量。

他举了一个例子来说明小鹏训练数据量之大:
春节期间,全国通用AI数字模型每日消耗量在0.737亿Tokens,小鹏车型全量运行时的日Token消耗量则达到了58.8万亿,是全国通用AI消耗的80倍。
从这个维度也可以看出,物理AI比数字AI复杂的程度之大。
因此,必须要有足够算力和数据处理能力作为基础,才能真正做好物理AI,做好自动驾驶。



过去一年中,小鹏仿真case数量从3万个增加到50万个,一天的测试当量相当于驾驶员去跑3000万公里的测试数据。
小鹏也将世界模型大量应用于仿真测试里面,以生成更自然、更有交互性的场景。
包括利用世界模型去做强化学习训练(包括自我博弈、长时序推演),以及利用世界模型加速全球化部署。

刘先明也给自己设置了几个2026年度目标,他谈到,小鹏辅助驾驶在今年年底之前,安全接管里程要提升50倍、平均接管里程提升25倍、车端模型参数量提升到200亿以上。
以此为基础,小鹏辅助驾驶在中国道路将达到媲美特斯拉FSD在硅谷的能力,这是第一大目标。
同时,VLA+VLM的舱驾一体能力,Max版车型(单图灵芯片)的蒸馏版,Robotaxi的无人化运营,也将在2026年底前实现。
他与何小鹏对于第二代VLA有着同样的信心,认为这是小鹏和其他自动驾驶企业拉开差距的起点,也将是目前中国最好用的自动驾驶。
聊一聊我的感受:
这两年体验辅助驾驶车型,能够感受到各家体验在平滑提升,但没有哪一家实现跨越式升级,头部玩家都在一个台阶上,向上跳,通过新版本优化来刷新排名,有取得短暂领先身位的选手,也有能力回落排名下滑的选手。
整体而言,第一梯队选手在95%的普通难度城区场景解题都很好,核心差异体现在通行效率的差异、车控细腻的差异。
但面对5%的困难场景,所有选手还是会慌张、会卡壳、会摆烂。
小鹏第二代VLA发布会上,何小鹏没有过多地聊技术概念,把演讲的重心正是放在了讲解5%的困难场景上,从现场的视频展示来看,第二代VLA对于困难场景的解题能力很强。
例如,快速绕行开门杀、黑夜绕行路面大坑、识别并让行宠物狗、极窄道路的会车博弈、交警手势的识别等等。
如果发布会上列举的场景都能稳定表现,那么小鹏第二代VLA确实将迎来一次智驾体验的跨越式提升。
这次发布会,小鹏第二代VLA吊足了胃口,具体什么时间能体验到?小鹏给了具体推送节奏:
小鹏第二代VLA推送会在3月下旬开启推送,首批车型覆盖全新小鹏P7 Ultra、小鹏G7 Ultra,以及小鹏X9 Ultra/Ultra SE。
4月开启全面推送,将覆盖所有Ultra和Ultra SE车型。
具体表现怎么样,相信我们很快就能体验到了,我们也将基于《Xauto智驾榜》路线和规则进行体验,到时再给大家做更详细的汇报。

京ICP备09113703号-1
信息网络传播视听节目许可证: 0110553
广播电视节目制作经营许可证
公司名称:北京车之家信息技术有限公司
中央网信办违法和不良信息举报中心
违法和不良信息举报电话:400-868-5856
举报邮箱:jubao@autohome.com.cn